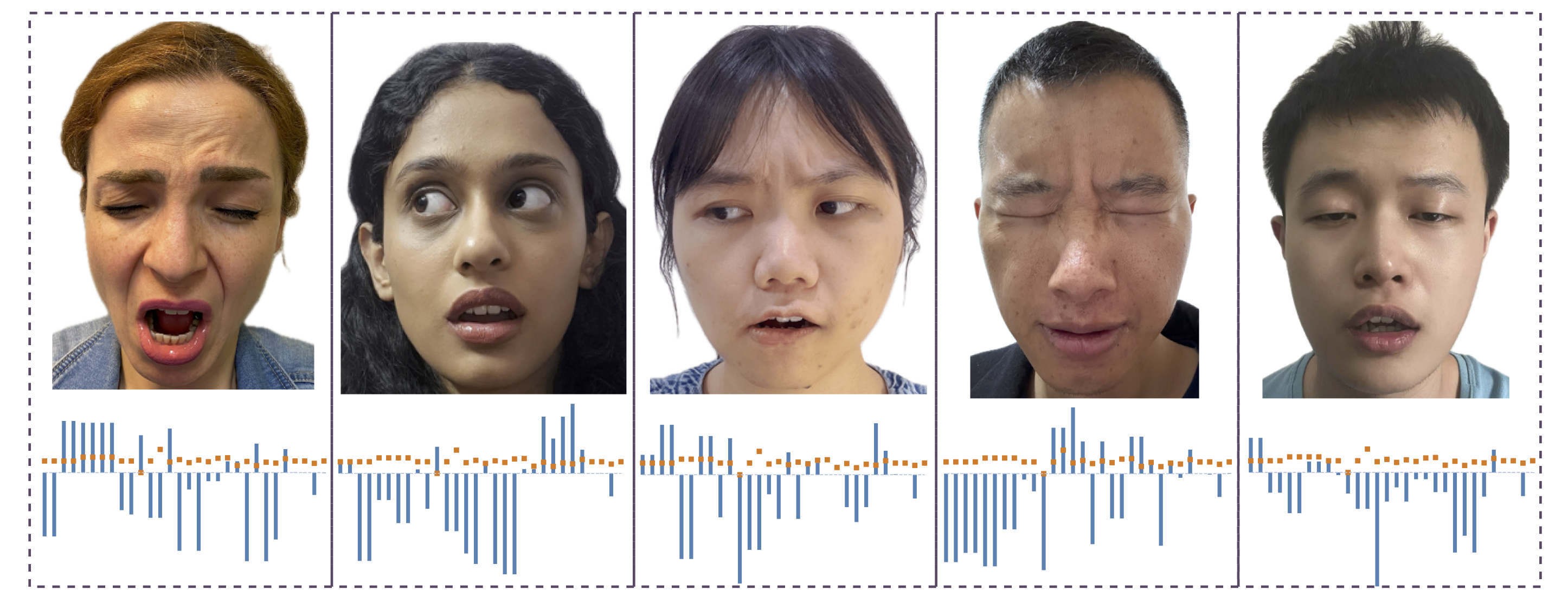
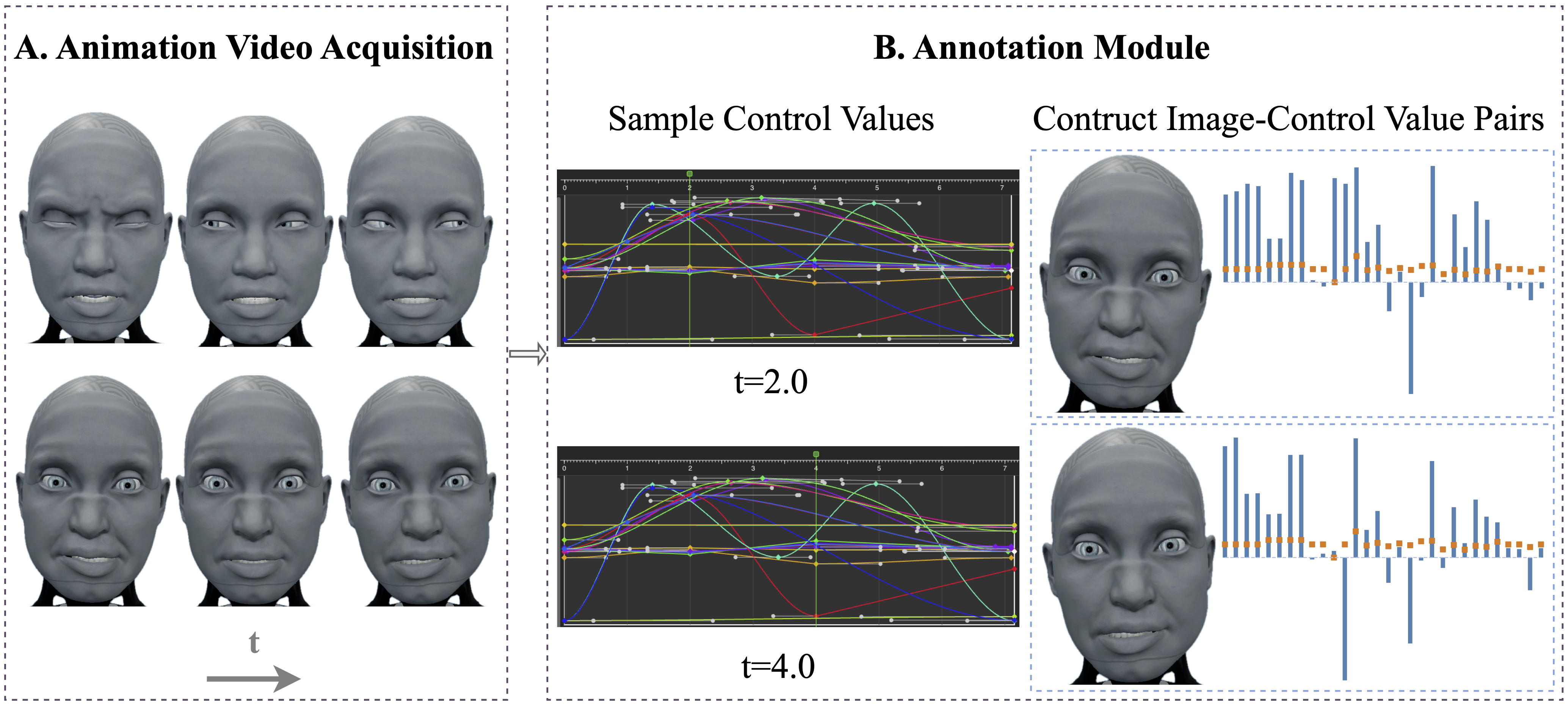
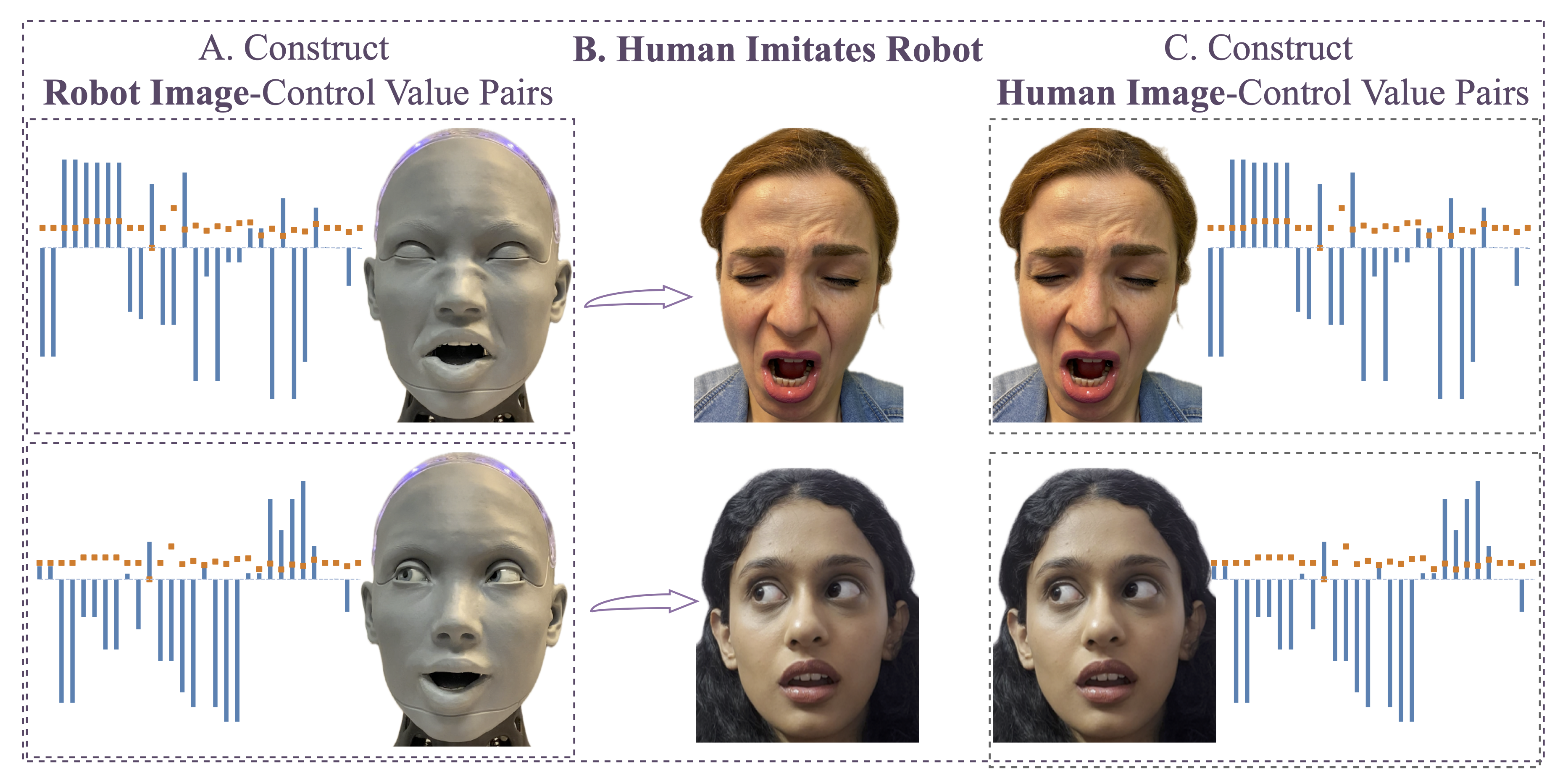
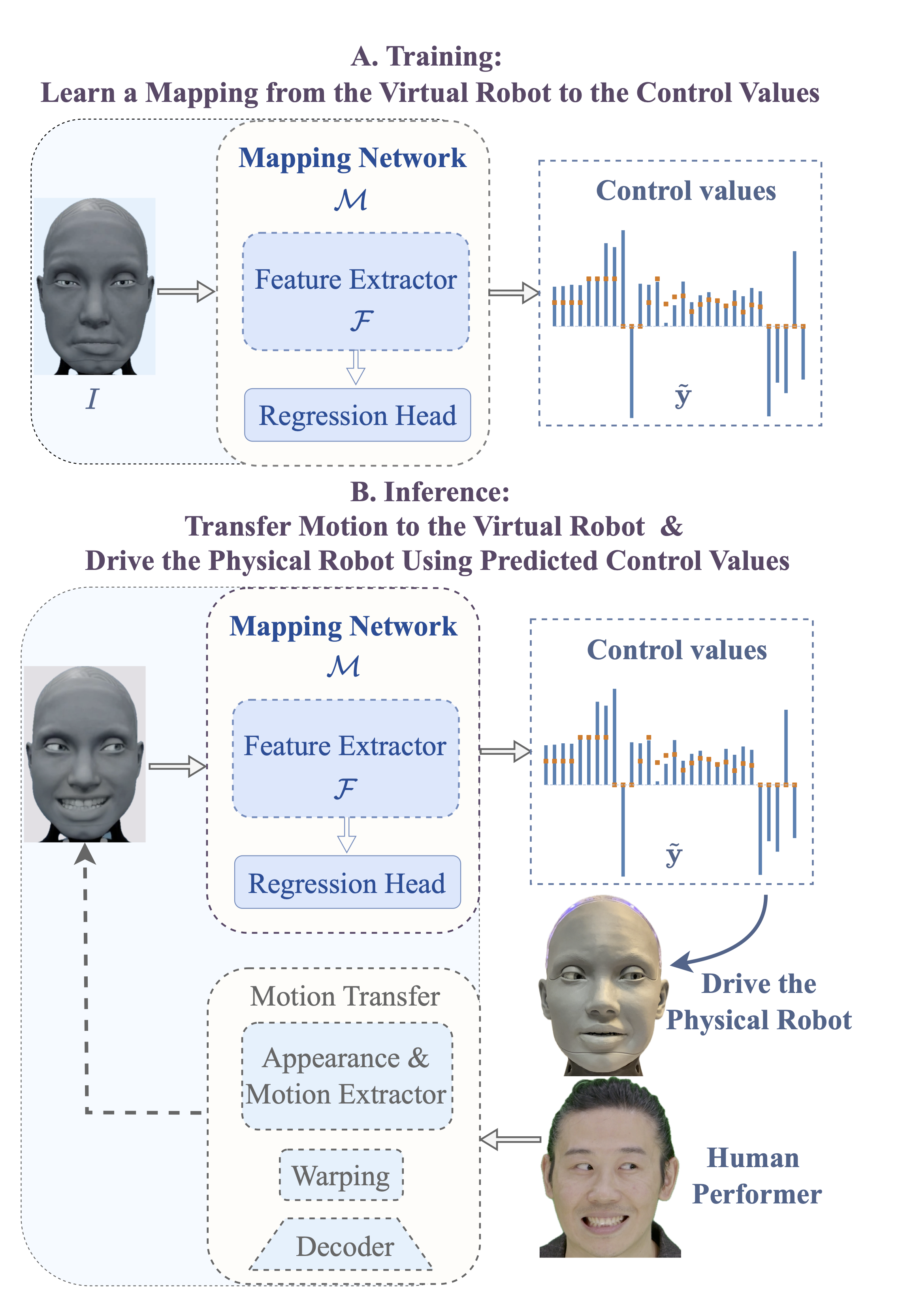
We present a new benchmark along with a novel human-to-robot motion transfer baseline that enables a humanoid robot to realistically imitate nuanced facial expressions from humans. Prior work on human facial expression imitation for humanoid robots typically operates within limited emotion categories, failing to capture the subtle emotional nuances inherent in human expressions, thereby hindering realistic imitation. To this end, we introduce X2C (Anything to Control), the first benchmark featuring nuanced facial expressions for realistic humanoid imitation. X2C comprises a training set and a test set. The training set consists of 104,987 images of a virtual humanoid robot in a simulation environment, each depicting nuanced facial expressions and annotated with 30 low-level control values. The test set contains nuanced human facial expressions with the same control value annotations as in the training set. Equipped with this benchmark, we propose Mimetician, a novel human-to-robot motion transfer baseline for realistic imitation. In this framework, a mapping network is trained using X2C to map images of the virtual robot to control values that encode emotional nuances within the robot's action space. Extensive experiments are conducted both on the test set and the physical humanoid robot, with both quantitative and qualitative evaluations. For more details, please refer to our project page.