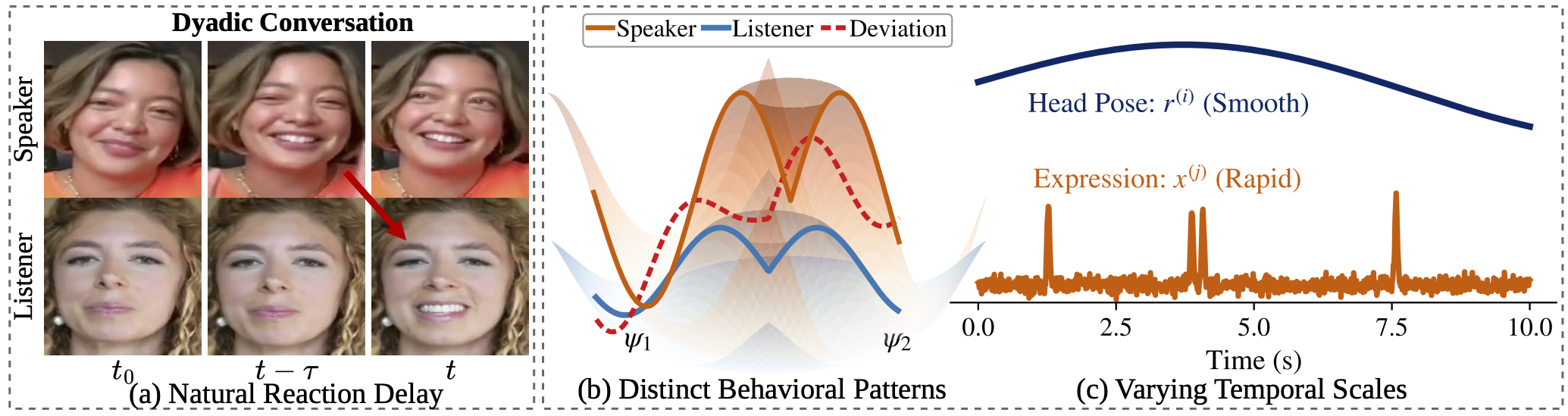
Generating responsive listener facial motion is a fundamental challenge in dyadic interactions, carrying profound implications for embodied conversational AI. However, existing approaches face two primary limitations. First, they fail to model listening as a fundamentally reactive process, often disregarding natural reaction delays and historical motion context. Because active speakers produce pronounced signals while listeners remain predominantly quiescent, lacking a mechanism to reconcile these distinct behavioral profiles causes generated motions to unnaturally deviate from the listener's ground truth. Second, they ignore varying temporal scales, failing to separate smooth head movements from rapid facial expressions.
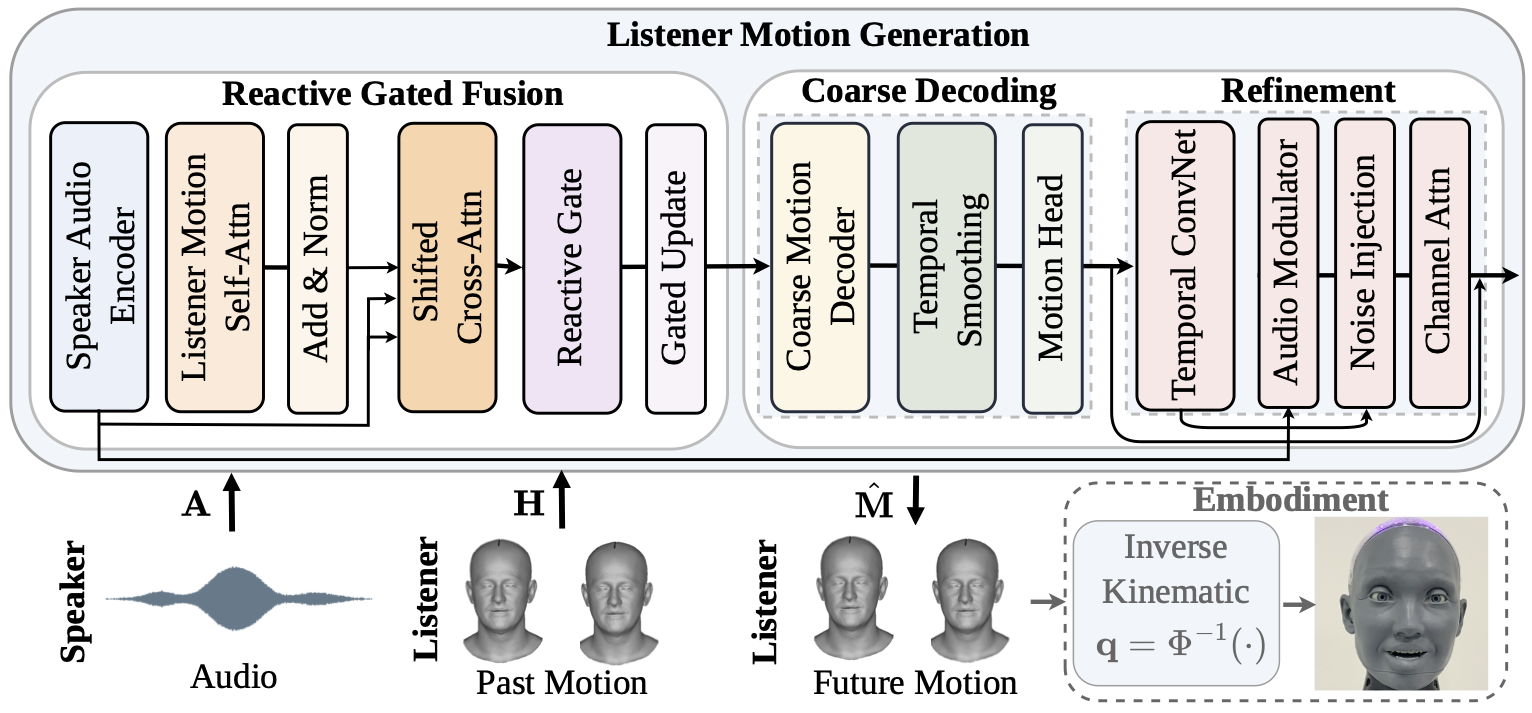
To address these issues, we propose REALM (Reactive Embodied Audio-driven Listening Model), a coarse-to-fine generative framework explicitly designed for audio-driven reactive listening. To capture this reactive nature and prevent unnatural deviation, we introduce a Reactive Gated Speaker-Listener Fusion module. It leverages a shifted variant of Attention with Linear Biases (ALiBi) to model realistic reaction delays, while a gating mechanism dynamically balances the speaker's acoustic trigger against the listener's motion history. To resolve temporal scale mismatches, a coarse decoder establishes smooth trajectories for head pose and expressions, followed by a refinement module that injects audio-modulated stochastic noise into expression features to synthesize lifelike, high-frequency subtleties.
Extensive evaluations demonstrate that REALM outperforms state-of-the-art baselines in both distributional realism and temporal synchrony. Finally, we validate our model's physical viability by deploying the synthesized motions onto a humanoid robot, bridging the gap between digital avatars and physically embodied agents.